Learning to Imagine: Diversify Memory for Incremental Learning using Unlabeled Data
Yu-Ming Tang1,3*, Yi-Xing Peng1,3*, Wei-Shi Zheng1,2,3
1School of Computer Science and Engineering, Sun Yat-sen University, China
2Peng Cheng Laboratory, Shenzhen, China
3Key Laboratory of Machine Intelligence and Advanced Computing, Ministry of Education, China
Introduction
Deep neural network (DNN) suffers from catastrophic forgetting when learning incrementally, which greatly limits its applications. Although maintaining a handful of samples (called “exemplars”) of each task could alleviate forget- ting to some extent, existing methods are still limited by the small number of exemplars since these exemplars are too few to carry enough task-specific knowledge, and therefore the forgetting remains. To overcome this problem, we propose to “imagine” diverse counterparts of given exemplars referring to the abundant semantic-irrelevant information from unlabeled data. Specifically, we develop a learnable feature generator to diversify exemplars by adaptively generating diverse counterparts of exemplars based on seman- tic information from exemplars and semantically-irrelevant information from unlabeled data. We introduce semantic-contrastive learning to enforce the generated samples to be semantic consistent with exemplars and perform semantic-decoupling contrastive learning to encourage diversity of generated samples. The diverse generated samples could effectively prevent DNN from forgetting when learning new tasks. Our method does not bring any extra inference cost and outperforms state-of-the-art methods on two benchmarks CIFAR-100 and ImageNet-Subset by a clear margin.
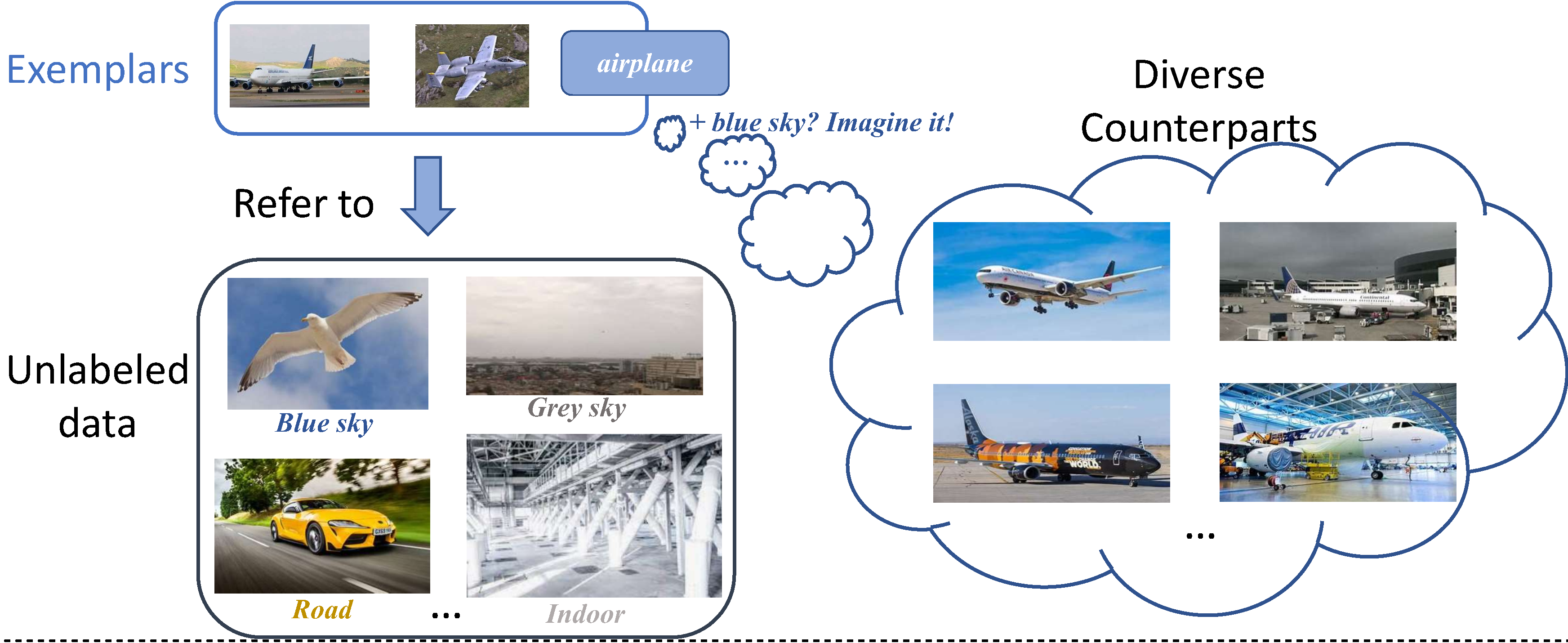
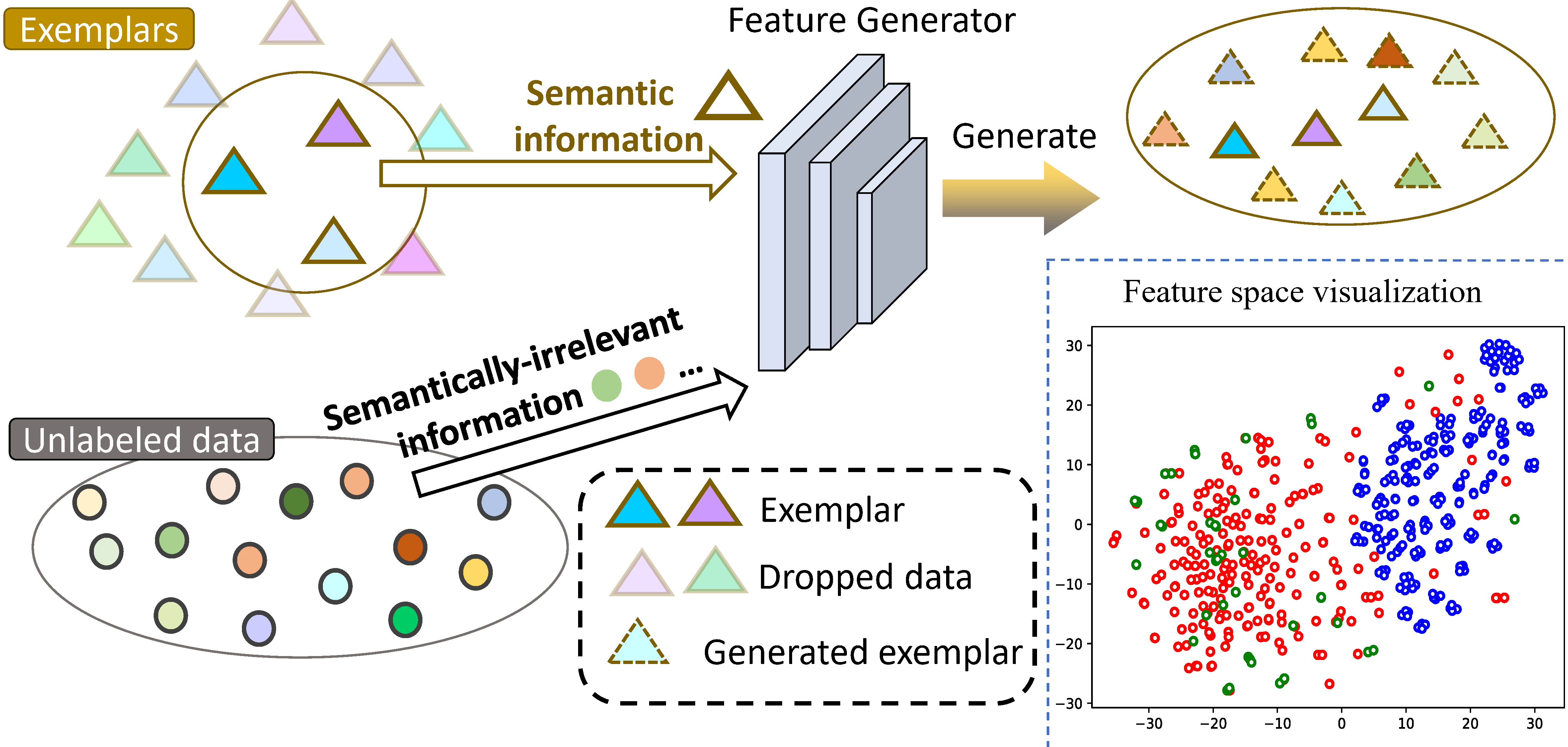
Figure 1. Our motivation (upper) and Illustration of our method alongside with TSNE visualization (bottom).
.png)
Citation
If you use this paper/code in your research, please consider citing us:
- Yu-Ming Tang, Yi-Xing Peng, Wei-Shi Zheng, "Learning to Imagine: Diversify Memory for Incremental Learning using Unlabeled Data", Proceedings of the IEEE conference on Computer Vision and Pattern Recognition (CVPR), 2022.