PSLT: A Light-weight Vision Transformer with Ladder Self-Attention and Progressive Shift
Gaojie Wu1,3, Wei-Shi Zheng1,2,3,*, Yutong Lu1, Qi Tian4
1School of Computer Science and Engineering, Sun Yat-sen University, China
2Peng Cheng Laboratory, Shenzhen, China
3Key Laboratory of Machine Intelligence and Advanced Computing, Ministry of Education, China
4Cloud & AI BU, Huawei
*Corresponding author
Introduction
Vision Transformer (ViT) has shown great potential for various visual tasks due to its ability to model long-range dependency. However, ViT requires a large amount of computing resource to compute the global self-attention. In this work, we propose a ladder self-attention block with multiple branches and a progressive shift mechanism to develop a light-weight transformer backbone that requires less computing resources (e.g. a relatively small number of parameters and FLOPs), termed Progressive Shift Ladder Transformer (PSLT). First, the ladder self-attention block reduces the computational cost by modelling local self-attention in each branch. In the meanwhile, the progressive shift mechanism is proposed to enlarge the receptive field in the ladder self-attention block by modelling diverse local self-attention for each branch and interacting among these branches. Second, the input feature of the ladder self-attention block is split equally along the channel dimension for each branch, which considerably reduces the computational cost in the ladder self-attention block (with nearly 1/3 the amount of parameters and FLOPs), and the outputs of these branches are then collaborated by a pixel-adaptive fusion. Therefore, the ladder self-attention block with a relatively small number of parameters and FLOPs is capable of modelling long-range interactions. Based on the ladder self-attention block, PSLT performs well on several vision tasks, including image classification, objection detection and person re-identification. On the ImageNet-1k dataset, PSLT achieves a top-1 accuracy of 79.9% with 9.2M parameters and 1.9G FLOPs, which is comparable to several existing models with more than 20M parameters and 4G FLOPs.
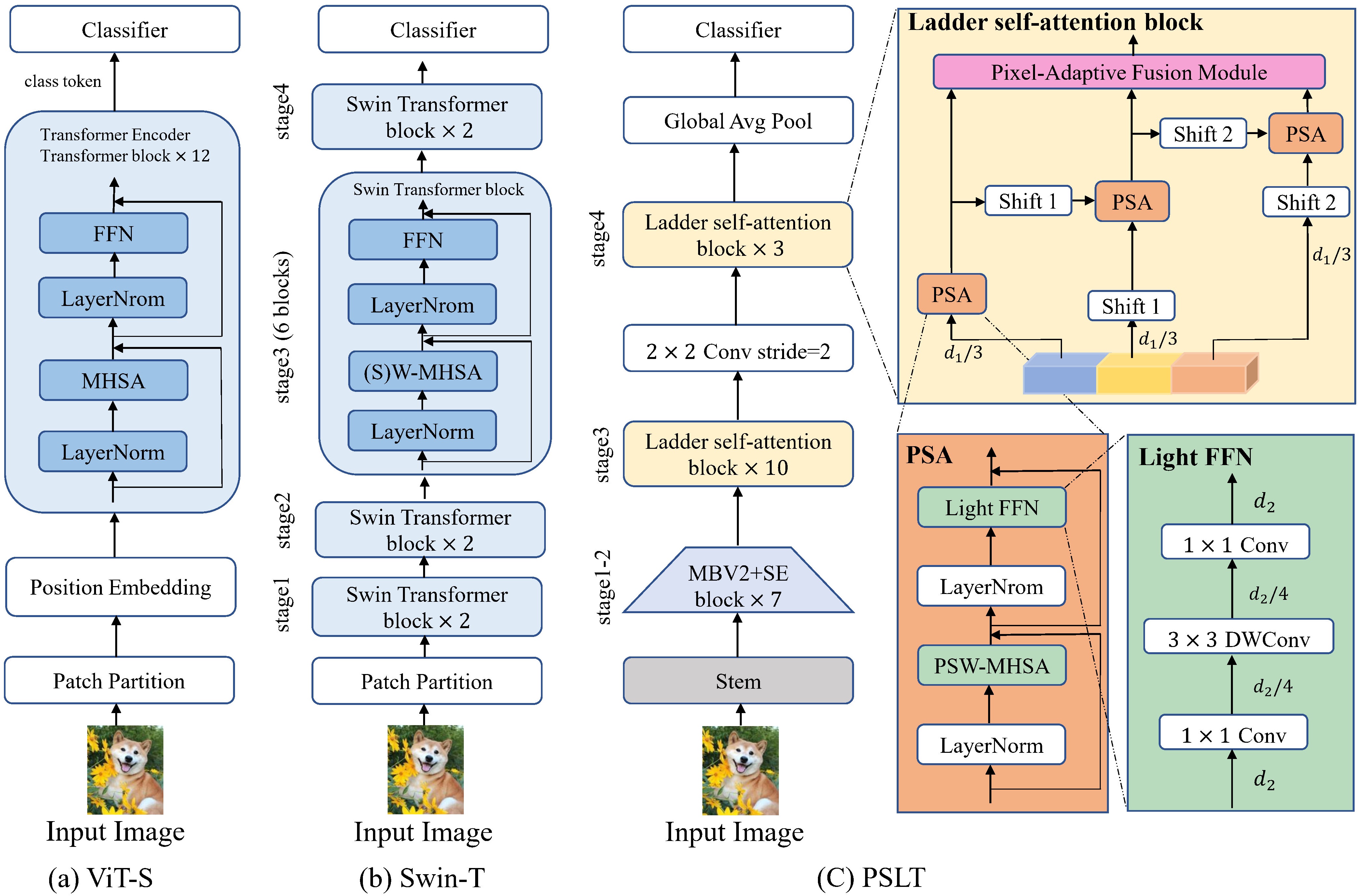 Figure 1. The comparison of PSLT with other models. Click on the image for higher resulution.
Figure 1. The comparison of PSLT with other models. Click on the image for higher resulution. Figure 2. Example of the ladder self-attention block and the pixel-adaptive fusion module. Click on the image for higher resulution.
Figure 2. Example of the ladder self-attention block and the pixel-adaptive fusion module. Click on the image for higher resulution.With the progressive shift mechanism, the ladder self-attention block is capble of aggregating features from diverse spatial windows.
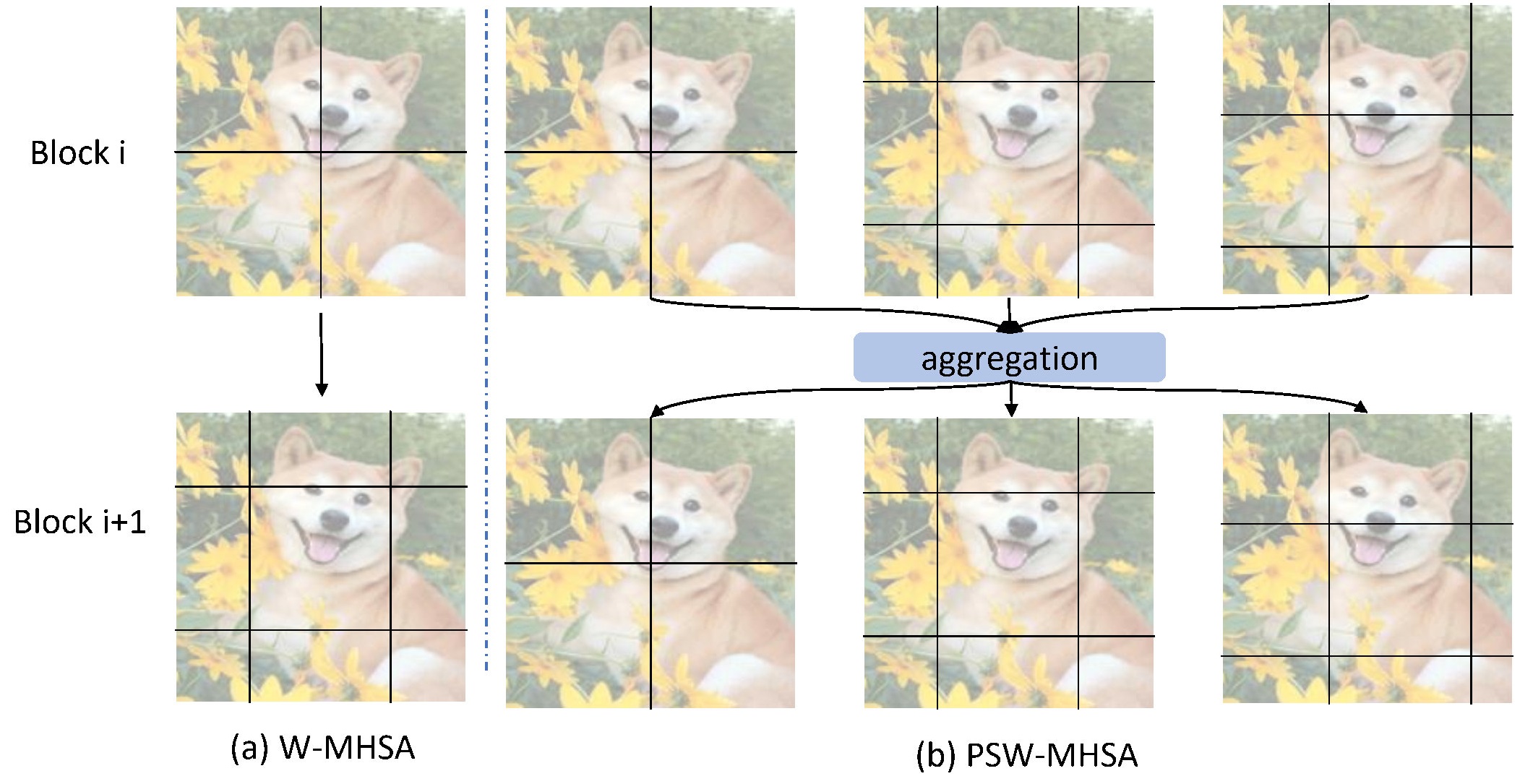
Figure 3. Comparison of window partition for pixel interactions in different self-attention block.
ImageNet classification results
Without utilizing the carefully designed neural architecture search algorithm, our PSLT achieves 79.9% top-1 accuracy with only 9.2M parameters, which is slightly higher than models with more than 10M parameters, such as ResT-Small (79.6% top-1 accuracy with 13.7M parameters) and DeiT-S (79.8% top-1 accuracy with 22.0M parameters). PSLT-Large with 16.0M parameters and 3.4G Flops achieves slightly higher top-1 accuracy than Swin (81.5% v.s. 81.3%) with 29.0M parameters and 4.5G Flops. The code and trained models can be downloaded here:
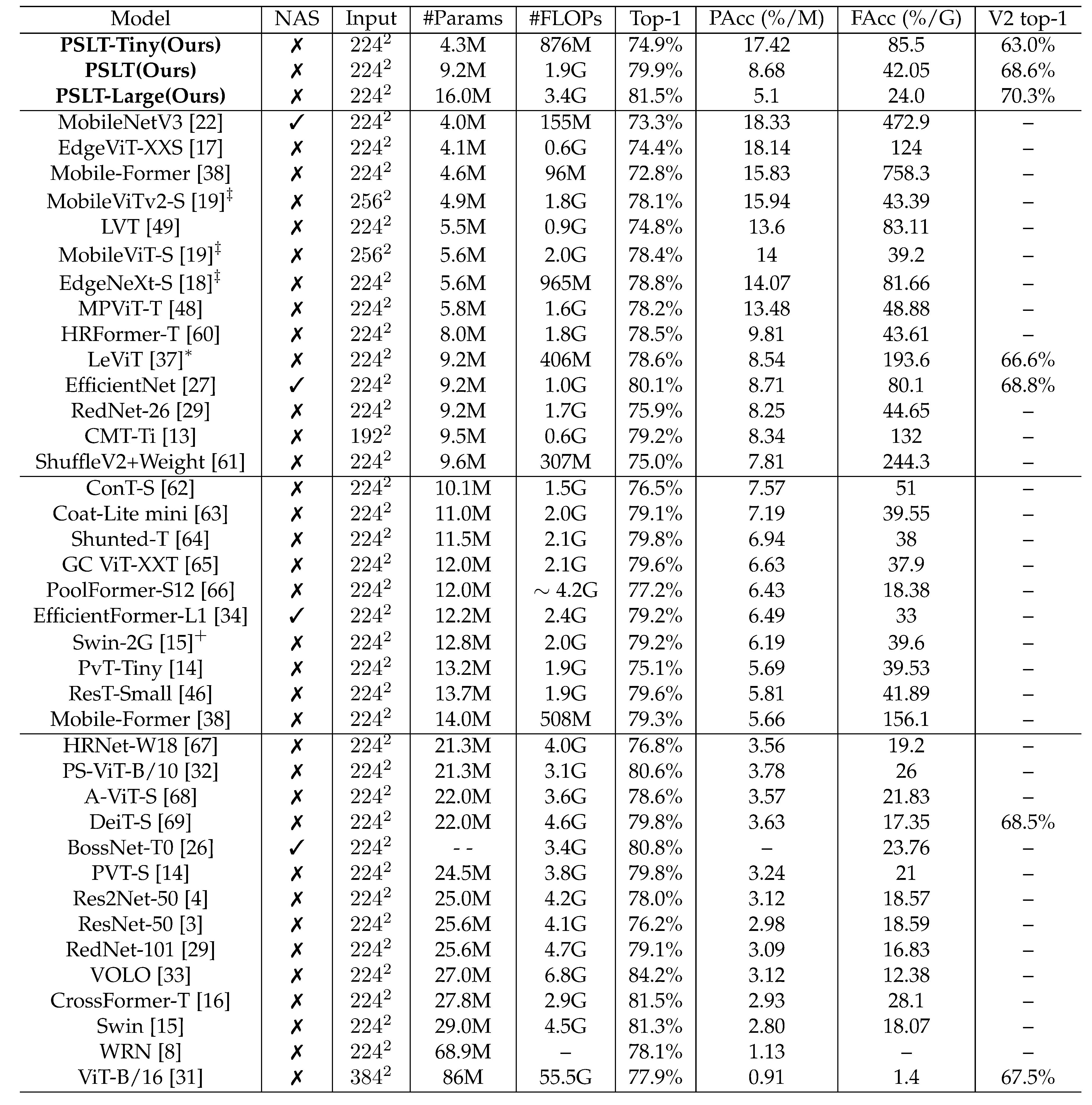 Table 1. Image Classification performance on the ImageNet without pretraining.
Table 1. Image Classification performance on the ImageNet without pretraining.Performance on downstream tasks
Our PSLT achieves comparable object detection and instance segmentation performance on COCO, semantic segmentation performance on ADE20k with relative less parameters.
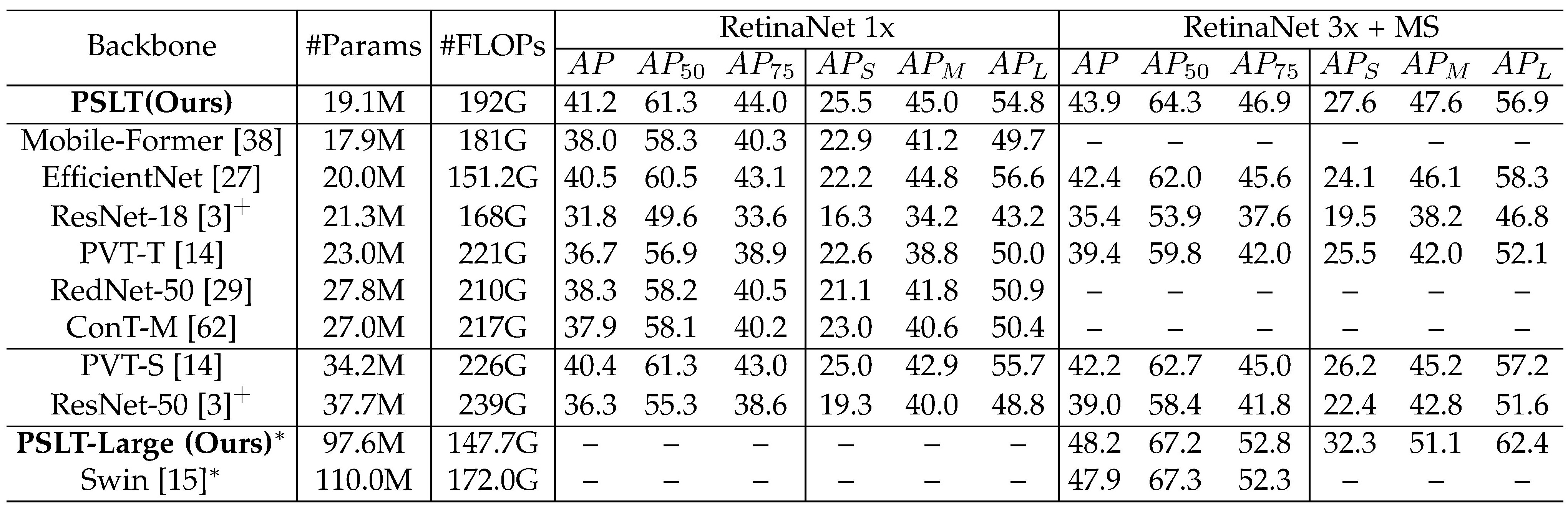 Table 2. Object detection performance on COCO.
Table 2. Object detection performance on COCO.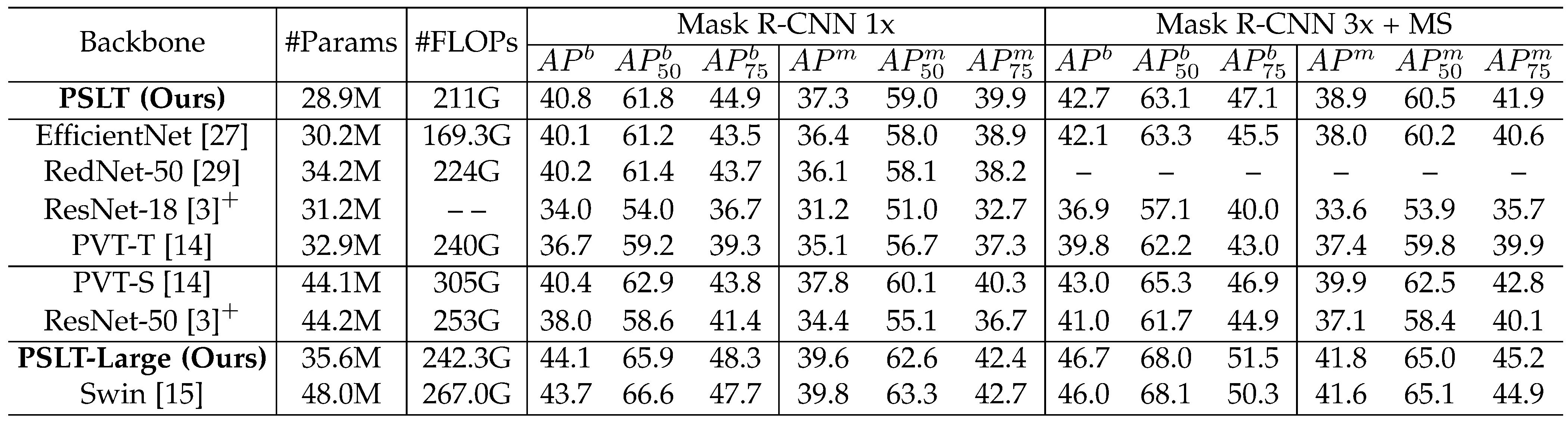 Table 3. Object detection and instance segmentation performance on COCO.
Table 3. Object detection and instance segmentation performance on COCO.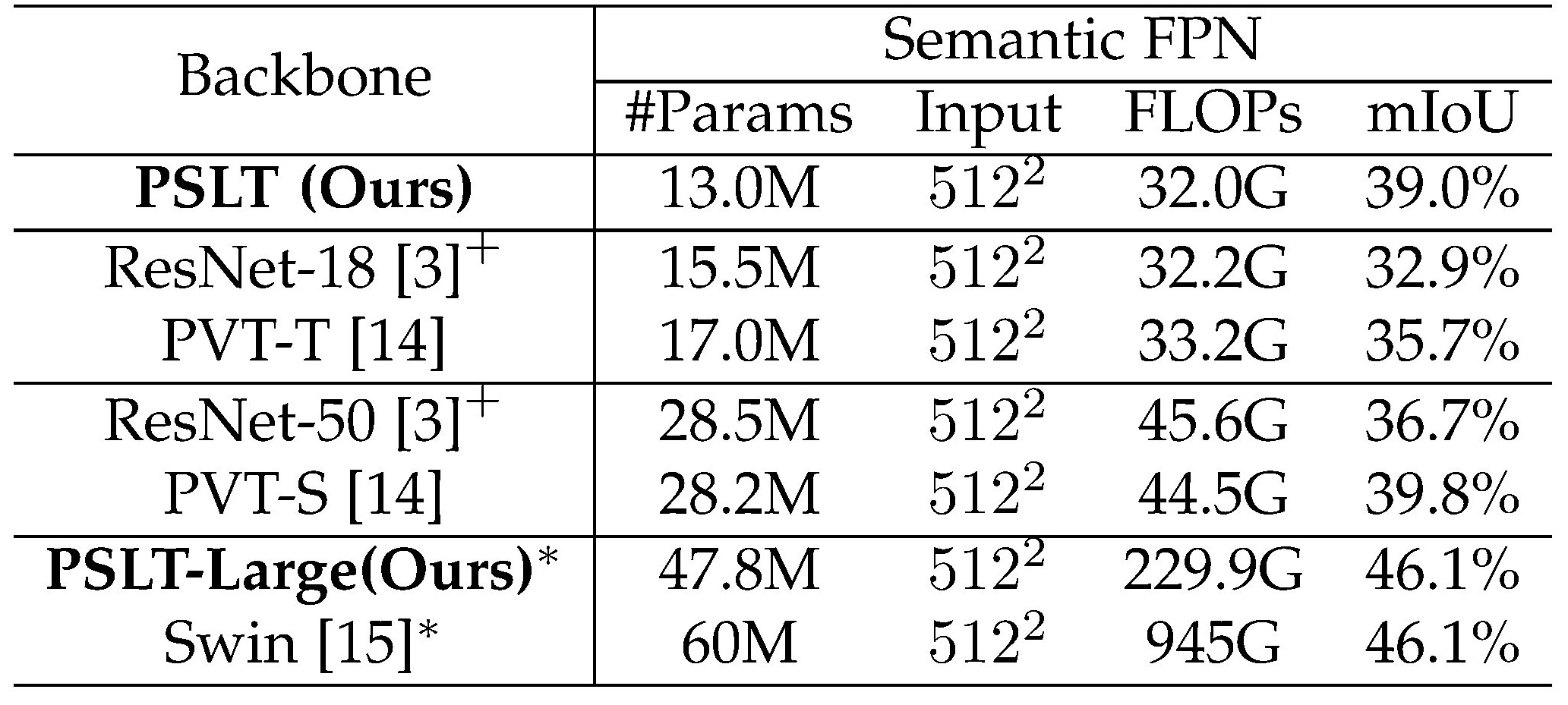
Table 4. Semantic segmentation performance on ADE20k.
A demo of detection and segmentation is illustrated below for PSLT.

Figure 4. Demo of PSLT on detectiono and segmentation.
For more details, please refer to the paper.
Citation
If you use this paper/code in your research, please consider citing us:
- Gaojie Wu, Wei-Shi Zheng, Yutong Lu, Qi Tian "PSLT: A Light-weight Vision Transformer with Ladder Self-Attention and Progressive Shift", IEEE Transaction on Pattern Analysis and Machine Intelligence, 2023.